2017年1月15日15:08:14
使用中文进行人机交互,过程很简单:接收用户输入的城市,打印出该城市对应的天气。之前的代码实现了天气数据的读取、存储与检索,离人机交互的目标还有一段距离。
构思人机交互过程,可以拟定出如下步骤:
- 程序启动,提示用户输入城市名称。
- 用户输入城市名称。
程序根据城市名称去检索天气。
3.1 程序打开天气数据文件。
3.2 程序解析天气数据文件,将其存储为字典。
3.3 程序根据用户输入的城市名称去检索字典,找到城市对应的天气。
程序将检索结构打印出来。
以上面的步骤重构之前的代码可得:
# -*- coding: utf-8 -*-
import sys
encoding_type = sys.getfilesystemencoding()
query_city = raw_input("宝宝,请你输入你要查询的城市:")
with open('weather_info.txt') as weather_info:
# Create one black dictionary to store weather data.
weather_report = {}
# Insert <city, weather> into dictionary.
for line in weather_info:
pair = line.split(',')
weather_report[pair[0]] = pair[1]
# Print weather of the city user specified from dictionary.
print weather_report[query_city].decode('utf-8').encode(encoding_type)
第一个问题
来自如上代码的第一个反馈是:“卧槽,怎么又出乱码了?”
lianbche@5CG44636XG D:\Learning\git\Py103\Chap1\project
> python Coderound3_UserInteraction.py
瀹濆疂锛岃浣犺緭鍏ヤ綘瑕佹煡璇㈢殑鍩庡競锛
在读写天气数据小结当中已经解决了一个乱码问题,所以这个时候再出现就有些诧异。于是,我去读了一遍IdxPy103Reference中指定的一篇廖雪峰有关编码的参考文章:字符串和编码,有两个收获:
- 自己之前有关编码的理解有一个地方有误:源代码文件中声明的编码格式的目的在于该文件在被解析时的编码格式,而不是自己之前所认为的“源代码本身所存储的格式”,之前没有问题是因为我当前的编辑器的编码格式碰巧为utf-8。

- 基本确信当前乱码的问题在什么地方:当前用来执行程序的CLI的编码方式不是utf-8,所以才显示乱码。查看当前使用命令行工具ConEmu的配置,Font charset设置为“Default”,而其中的可选字符集并没有utf-8,基本确认问题为CLI的字符编码不匹配。
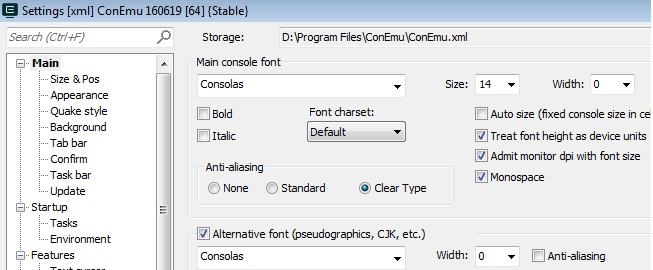
解决ConEmu
其实上面的问题与之前的问题原理是一样的,都是由于“Python输出中文的编码格式”与“ConEmu CLI工具的编码格式”不一致所导致,解决方法有两种:第一种,在调用print输出中文时将其转换为“CLI工具支持的编码格式”,这是解决<
在网上搜索了好几篇文章,最终在ConEmu github页面找到可靠的信息,上面指明通过chcp命令来查看、设置CLI支持的编码方式,比如查看当前默认的编码方式:
lianbche@5CG44636XG C:\Users\lianbche
> chcp
Active code page: 936
lianbche@5CG44636XG C:\Users\lianbche
>
936的编码方式,WIKI里提到这是简体中文的一种编码方式,结合Python字符编码详解里面的介绍它还有另外一个名字,即“GBK”,在Windows的官方介绍.aspx)里面它最为精确的名字是“GB2312”。说这么多其实反正就一条:它不是utf-8对应的code page。
utf-8在对应的code page为65001,在ConEmu里面使用chcp 65001将编码格式设置为utf-8之后重新测试,便可以正常显示中文了。
Active code page: 65001
lianbche@5CG44636XG D:\Learning\git\Py103\Chap1\project
> python Coderound3_UserInteraction.py
宝宝,请你输入你要查询的城市:
EOFError错误
继续调试代码,出现了另外一个问题:
Active code page: 65001
lianbche@5CG44636XG D:\Learning\git\Py103\Chap1\project
> python Coderound3_UserInteraction.py
宝宝,请你输入你要查询的城市:杭州
Traceback (most recent call last):
File "Coderound3_UserInteraction.py", line 6, in <module>
query_city = raw_input("宝宝,请你输入你要查询的城市:")
EOFError
问题出现在第6行query_city = raw_input("宝宝,请你输入你要查询的城市:"),为什么会有这个错误呢?
从stackoverflow上的一篇问答上得知该问题的原因是因为没有从终端上读取到可以识别的输入。看来十有八九仍旧是编码问题。
几番测试之后依然搞不定,干脆直接到ComEmu CLI上调用python打印中文,发现一旦打印python就会直接退出。
lianbche@5CG44636XG D:\Learning\git\Py103\Chap1\project
> python
Python 2.7.2 (default, Jun 12 2011, 15:08:59) [MSC v.1500 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print '中文'
lianbche@5CG44636XG D:\Learning\git\Py103\Chap1\project
>
明天要交作业,所以马上更换Windows自带的Power Shell调试,发现并没有这个问题,赶紧修改代码:
# -*- coding: utf-8 -*-
import sys
encoding_type = sys.getfilesystemencoding()
query_city = raw_input(u"宝宝,请你输入你要查询的城市:".encode(sys.stdin.encoding)).decode(sys.stdin.encoding).encode('utf-8')
with open('weather_info.txt') as weather_info:
# Create one black dictionary to store weather data.
weather_report = {}
# Insert <city, weather> into dictionary.
for line in weather_info:
pair = line.split(',')
weather_report[pair[0]] = pair[1]
# Print cities in dictionary.
print weather_report[query_city].decode('utf-8').encode(encoding_type)
测试,正常。有没有发现raw_input那一行的代码特别长,说实话我也不想,但是现在已经被前一个问题折腾得差点走火入魔,等我把任务提交了再回来。
PS D:\Learning\git\Py103\Chap1\project> python .\Coderound3_UserInteraction.py
宝宝,请你输入你要查询的城市:杭州
毛毛雨/细雨
PS D:\Learning\git\Py103\Chap1\project>